svm是什么?啦啦,这个问题说起来比较费劲,感兴趣的话可以去看看这篇知乎大佬写的文章
本文要说的是svm能做什么,以及怎么用代码来做。
1 svm能做什么
先看下面这个例子:
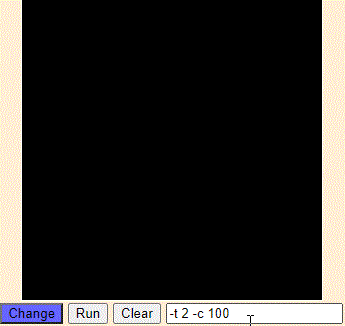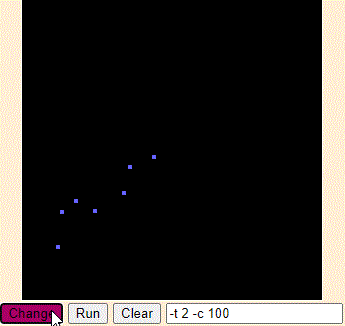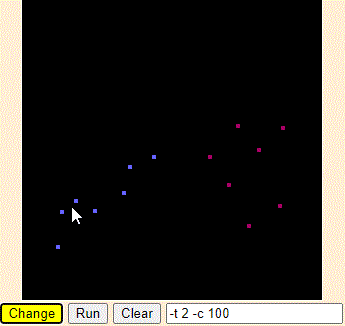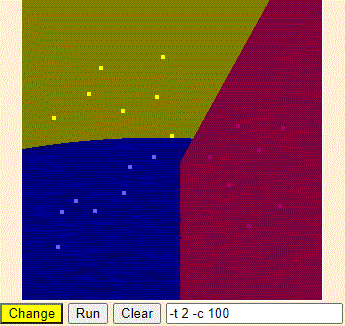
在平面坐标系上画了红黄蓝种颜色的点若干个,然后我们画几条线,把平面划分为三个区域,使得相同颜色的点落在同一区域内。
如此一来,给出任意一个点的坐标,我们就能确定它落在哪个区域内,从而将它分类。
用稍微数字化一点的表达就是,svm能解决下列问题:
| 已知:
当x=[1,2]时,y='红';
当x=[3,2]时,y='红';
当x=[4,3]时,y='黄';
当x=[5,1]时,y='黄';
当x=[2,6]时,y='蓝';
....
求:
当x=[3,7]时,y=?
|
最常见的用途就是验证码识别:我们把读取验证码图片上各像素点的灰度值(0~255),得到了一个向量,然后手工录入这张图片上的字母,形成样本,把很多张图片样本经过训练后得到一个svm模型。
此后,我们传入一张新图片,就能知道图片上有什么字母了。(当然,这只是个理想过程,实际上还要辅以一些图像预处理手段等等)
2 libsvm-java的使用示例
libsvm-java 是最著名的svm java库。
下面的例子中,我们用svm来判断某个属于哪个象限。
有同学要问,判断象限用x、y的正负不就可以了么?是的,这个例子是可以用公式直接判断的,正是因为它简单,我们才能简洁地说明svm的步骤,并能方便地构造样本和验证结果。
理解了这个简单的套路,在图像识别等复杂得无法用公式判断的场景,我们也可以按这个套路进行。
2.1 安装
引入maven依赖即可使用
| <dependency>
<groupId>tw.edu.ntu.csie</groupId>
<artifactId>libsvm</artifactId>
<version>3.24</version>
</dependency>
|
然而这个库用起来相当恶心:完全c语言的命名风格,用System.out.println来打印日志等等。。好在源码数量不多。
所以,建议你先用maven依赖跑起来熟悉一下,正式使用时从 https://github.com/cjlin1/libsvm/tree/master/java 上把源码拷下来自己把觉得恶心的地方改掉。
2.2 构造样本
前面说了,判断象限可以直接用x、y的正负,所以我们先写一个判断象限的方法,并以此随机生成样本:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
private static int getQuadrant(double x, double y) {
if (x > 0) {
if (y > 0) {
return 1;
} else {
return 2;
}
} else {
if (y > 0) {
return 4;
} else {
return 3;
}
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
final int sampleNum = 100;
double[][] features = new double[sampleNum][];
double[] targetValues = new double[sampleNum];
Random random = new Random(233);
for (int i = 0; i < sampleNum; i++) {
double x = random.nextInt(200) - 100;
double y = random.nextInt(200) - 100;
int quadrant = getQuadrant(x, y);
double normalizationX = (x + 100) / 200;
double normalizationY = (y + 100) / 200;
features[i] = new double[]{normalizationX, normalizationY};
targetValues[i] = quadrant;
|
2.3 训练模型
有了样本,我们就可以拿来训练了,写一个训练的方法,除了调参的部分,这个方法是可以复用的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
private static svm_model train(double[][] features, double[] targetValues) {
svm_node[][] svmNodes = new svm_node[features.length][features[0].length];
for (int i = 0; i < features.length; i++) {
double[] feature = features[i];
for (int i1 = 0; i1 < feature.length; i1++) {
svm_node svmNode = new svm_node();
svmNode.index = i1 + 1;
svmNode.value = feature[i1];
svmNodes[i][i1] = svmNode;
}
}
svm_problem sp = new svm_problem();
sp.x = svmNodes;
sp.y = targetValues;
sp.l = features.length;
svm_parameter prm = new svm_parameter();
prm.svm_type = svm_parameter.C_SVC;
prm.kernel_type = svm_parameter.RBF;
prm.C = 1000;
prm.eps = 0.0000001;
prm.gamma = 10;
prm.probability = 1;
prm.cache_size = 1024;
svm_model model = svm.svm_train(sp, prm);
return model;
}
|
然后传入刚才生成的样本,即可训练出一个模型对象:
| svm_model model = train(features, targetValues);
|
这里我们看到了libsvm的恶心之处,对象名svm_model居然是小写+下划线。。。
我们也可以把训练好的模型存入文件里,下次直接读文件获取模型而免去训练过程:
| svm.svm_save_model("d:/test.md", model);
svm_model model1 = svm.svm_load_model("d:/test.md");
|
2.4 识别分类
有了模型,我们就可以传入一个新向量来识别它是哪一类了:
|
svm_node[] test = new svm_node[]{new svm_node(), new svm_node()};
test[0].index = 1;
test[0].value = -45.5;
test[1].index = 2;
test[1].value = -20.2;
test[0].value = (test[0].value+100)/200;
test[1].value = (test[1].value+100)/200;
double result = svm.svm_predict(model, test);
System.out.println("所在象限 " + result);
|
完整代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
| package org.wowtools.test;
import libsvm.*;
import java.util.Random;
public class SvmTest {
public static void main(String[] args) {
final int sampleNum = 100;
double[][] features = new double[sampleNum][];
double[] targetValues = new double[sampleNum];
Random random = new Random(233);
for (int i = 0; i < sampleNum; i++) {
double x = random.nextInt(200) - 100;
double y = random.nextInt(200) - 100;
int quadrant = getQuadrant(x, y);
double normalizationX = (x + 100) / 200;
double normalizationY = (y + 100) / 200;
features[i] = new double[]{normalizationX, normalizationY};
targetValues[i] = quadrant;
}
svm_model model = train(features, targetValues);
svm_node[] test = new svm_node[]{new svm_node(), new svm_node()};
test[0].index = 1;
test[0].value = -45.5;
test[1].index = 2;
test[1].value = -20.2;
test[0].value = (test[0].value+100)/200;
test[1].value = (test[1].value+100)/200;
double result = svm.svm_predict(model, test);
System.out.println("所在象限 " + result);
}
private static svm_model train(double[][] features, double[] targetValues) {
svm_node[][] svmNodes = new svm_node[features.length][features[0].length];
for (int i = 0; i < features.length; i++) {
double[] feature = features[i];
for (int i1 = 0; i1 < feature.length; i1++) {
svm_node svmNode = new svm_node();
svmNode.index = i1 + 1;
svmNode.value = feature[i1];
svmNodes[i][i1] = svmNode;
}
}
svm_problem sp = new svm_problem();
sp.x = svmNodes;
sp.y = targetValues;
sp.l = features.length;
svm_parameter prm = new svm_parameter();
prm.svm_type = svm_parameter.C_SVC;
prm.kernel_type = svm_parameter.RBF;
prm.C = 1000;
prm.eps = 0.0000001;
prm.gamma = 10;
prm.probability = 1;
prm.cache_size = 1024;
svm_model model = svm.svm_train(sp, prm);
return model;
}
private static int getQuadrant(double x, double y) {
if (x > 0) {
if (y > 0) {
return 1;
} else {
return 2;
}
} else {
if (y > 0) {
return 4;
} else {
return 3;
}
}
}
}
|

